
Yogyakarta, 30 Juni 2025 – Peneliti Departemen Ilmu Komputer dan Elektronika (DIKE), FMIPA UGM, mengembangkan studi empiris terkait kemampuan adaptasi model bahasa (language model) untuk menghadapi keragaman bahasa daerah di Indonesia. Melalui penelitian berjudul “Adapting Language Models to Indonesian Local Languages: An Empirical Study of Language Transferability on Zero-Shot Settings”, dilakukan pengujian terhadap kemampuan transfer model bahasa pada sepuluh bahasa daerah Indonesia, beberapa di antaranya termasuk pada kategori low-resource language. Penelitian ini dilakukan oleh Rifki Afina Putri, Ph.D., dosen sekaligus peneliti di Laboratorium Riset Sistem Cerdas, DIKE UGM. Penelitian ini berhasil diterima dan akan dipresentasikan pada International Conference on Advanced Machine Learning and Data Science (AMLDS 2025), tanggal 19-21 Juli 2025, di Tokyo, Jepang.
Studi ini mengevaluasi kinerja berbagai language model dalam menyelesaikan tugas analisis sentimen pada bahasa-bahasa daerah yang datanya tidak ada proses pelatihan awal (pre-training) model atau disebut sebagai zero-shot setting. Dengan kondisi Indonesia yang memiliki lebih dari 700 bahasa daerah, dan sebagian besar di antaranya masih belum memiliki sumber data digital maupun teknologi pemrosesan bahasa yang memadai, urgensi pengembangan sistem pemrosesan bahasa alami (NLP) yang inklusif menjadi semakin nyata. Tanpa upaya konkret ke arah ini, terdapat risiko semakin lebarnya kesenjangan digital antar bahasa, serta terpinggirkannya warisan linguistik yang menjadi bagian penting dari identitas budaya Indonesia. Penelitian ini diharapkan dapat menjembatani kesenjangan tersebut.
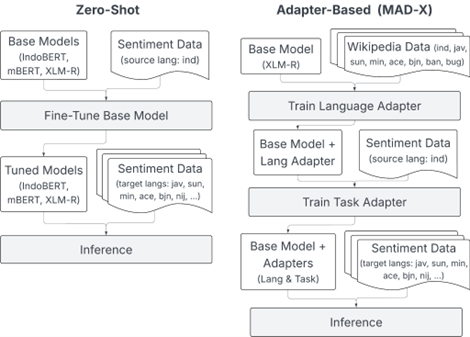
Gambar 1. Ilustrasi metode transfer learning yang diteliti pada studi ini.
Pendekatan yang digunakan dalam penelitian ini mencakup dua strategi utama, yaitu zero-shot transfer dan adapter-based (MAD-X) transfer. Pada pendekatan zero-shot, model bahasa seperti IndoBERT, mBERT, dan XLM-R dilatih menggunakan data dalam Bahasa Indonesia, lalu langsung diuji pada bahasa-bahasa daerah tanpa pelatihan tambahan. Hasilnya menunjukkan bahwa kinerja terbaik diperoleh pada bahasa yang sudah dikenal saat pelatihan awal (seperti Bahasa Indonesia dan Jawa), menurun pada bahasa yang berkerabat, dan paling rendah pada bahasa yang tidak pernah dikenal oleh model sebelumnya.
Untuk meningkatkan kinerja terutama pada bahasa yang tidak dikenal, digunakan metode adapter-based MAD-X. Dalam pendekatan ini, adapter bahasa dilatih terlebih dahulu menggunakan data Wikipedia unlabeled dari bahasa target, lalu dikombinasikan dengan task adapter yang dilatih menggunakan data Bahasa Indonesia. Pendekatan ini terbukti lebih efektif untuk sebagian besar bahasa lokal, bahkan pada beberapa kasus melampaui full fine-tuning, selama tersedia cukup data untuk pelatihan adapter bahasa.
Analisis tambahan terhadap tokenisasi menunjukkan bahwa tingkat keberhasilan transfer tidak hanya dipengaruhi oleh kesamaan kosakata atau jumlah potongan subword, tetapi lebih ditentukan oleh eksposur awal model terhadap bahasa dan kemampuannya membangun pemahaman kontekstual lintas bahasa.
Penelitian ini menegaskan pentingnya pengembangan strategi adaptasi model bahasa yang efisien dan inklusif, khususnya untuk bahasa-bahasa lokal Indonesia yang selama ini masih belum banyak terjangkau dalam pengembangan teknologi bahasa. Ke depan, pengembangan teknik adapter yang lebih fleksibel, perluasan korpus pre-training, serta eksplorasi metode zero-shot atau few-shot learning diharapkan dapat semakin memperluas jangkauan pengembangan NLP pada bahasa-bahasa minoritas, khususnya bahasa daerah di Indonesia.
Penelitian ini juga berkontribusi pada pencapaian Tujuan Pembangunan Berkelanjutan (SDGs), khususnya pada SDG 4 (Pendidikan Berkualitas), SDG 9 (Industri, Inovasi, dan Infrastruktur), serta SDG 10 (Pengurangan Kesenjangan) melalui pengembangan teknologi bahasa yang inklusif untuk menghadapi keberagaman bahasa di Indonesia.
Author: Lab SC – Rifki
Editor: Marina
#SDGs4 #SDGs9 #SDGs10



