

Yogyakarta, 28 Juli 2025 – Dr. Sri Mulyana, M.Kom., dosen Magister Kecerdasan Artifisial (MKA) dari Departemen Ilmu Komputer dan Elektronika (DIKE) FMIPA UGM, bersama alumni Program Studi Magister Komputer, Aszani, M.Kom., mengembangkan metode ekstraksi otomatis elemen user story menggunakan pendekatan Natural Language Processing (NLP). Penelitian ini mengangkat topik “Automatic Extraction of User Story Elements: NLP-Based Approach” dan menggabungkan teknik Named Entity Recognition (NER) dengan model tok2vec dan transformer.
Penelitian ini diawali dengan eksplorasi sistematis terhadap 50 artikel ilmiah dari Google Scholar yang terbit antara tahun 2019 hingga 2022. Semua artikel dipilih secara manual dengan fokus pada pengembangan perangkat lunak di bidang pendidikan. Proses labeling dilakukan untuk membedakan empat elemen utama dalam user story, yaitu aktor, tindakan, deskripsi, dan topik. Hasilnya, diperoleh dataset berlabel sebanyak 2.369 baris, mencakup ratusan entitas dari setiap kategori.
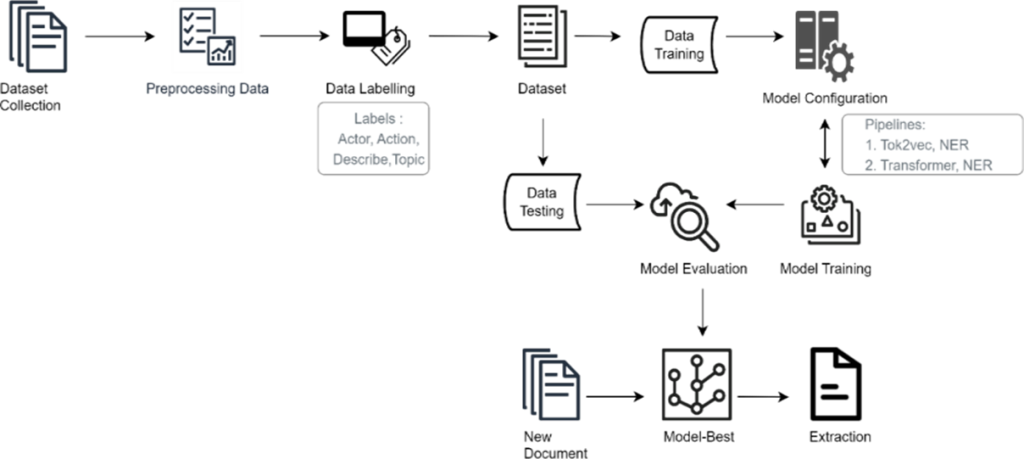
Hasil evaluasi kinerja menunjukkan perbedaan yang signifikan antara model tok2vec dan transformer dalam mengidentifikasi entitas di berbagai dokumen. Pada dokumen awal, model tok2vec mengidentifikasi 37 entitas, sementara model transformer mengenali 17 entitas. Meskipun jumlah entitas lebih sedikit, model transformer menghasilkan tingkat akurasi yang lebih tinggi yaitu 61,67%, dibandingkan model tok2vec yang hanya 42,26%. Sebaliknya, pada dokumen yang kedua, kedua model tidak berhasil mengidentifikasi entitas apa pun, hal ini menjadi keterbatasan dari kedua model tersebut dalam konteks tertentu. Sedangkan pada dokumen ketiga, model transformer mendeteksi 49 entitas dan model tok2vec mendeteksi 95 entitas. Meskipun jumlah entitas yang dihasilkan lebih rendah, model transformer mencapai akurasi yang lebih tinggi, yaitu 71,53%, sedangkan model tok2vec 65,73%. Demikian pula, pada dokumen keempat, kedua model mengidentifikasi 40 entitas, dan model transformer menunjukkan akurasi yang unggul, yaitu 75,00%, sedangkan model tok2vec 45,03%. Yang terakhir pada dokumen kelima, ternyata model transformer dapat mengidentifikasi 54 entitas dengan akurasi sempurna (100%), sementara model tok2vec mengenali 83 entitas dengan akurasi 62,29%.
Penelitian ini telah dipresentasikan pada forum ilmiah internasional International Conference on Advanced Machine Learning and Data Science (AMLDS) 2025 yang berlangsung di Tokyo, Jepang pada 19-21 Juli 2025. Partisipasi dalam konferensi ini menjadi bukti kontribusi DIKE UGM dalam bidang riset pemrosesan bahasa alami dan pengembangan perangkat lunak berbasis AI.
Riset ini juga berkontribusi dalam pencapaian Tujuan Pembangunan Berkelanjutan (SDGs), khususnya SDG 9: Industri, Inovasi, dan Infrastruktur. Melalui pemanfaatan NLP untuk meningkatkan pemahaman kebutuhan pengguna dalam pengembangan sistem, penelitian ini mendorong terciptanya ekosistem digital yang lebih cerdas.
Author: Sri Mulyana, Aszani
Editor: Marina
#SDGs9
